
How to Master Data Cleaning for High School Data Science Projects
Data cleaning is one of the most important steps in any data science project. For high school students exploring data science, mastering this skill will set the foundation for successful analysis, accurate insights, and compelling projects. In this guide, we will walk through what data cleaning is, why it's important, and the essential steps for mastering data cleaning for your high school data science projects.

1. What is Data Cleaning?
Data cleaning, also known as data cleansing or data preprocessing, is the process of identifying and fixing errors, inconsistencies, and inaccuracies in a dataset. It ensures that your data is accurate, reliable, and ready for analysis. In most data science projects, raw data often comes with missing values, duplicate entries, or incorrect formats, which can skew the results of your analysis.
Why is Data Cleaning Important?
Without clean data, your analysis might produce misleading results, leading to incorrect conclusions. A good data science project begins with well-prepared data. Data cleaning improves the quality of your dataset, allowing you to build accurate models and present reliable findings.
Relevant Resources:
2. Common Data Issues in High School Projects
Before diving into the steps for data cleaning, it’s essential to recognize the types of issues you’re likely to encounter in your high school data science projects:
- Missing Data: When some values are missing in your dataset, it can lead to incomplete analysis.
- Duplicate Data: Duplicates occur when multiple records represent the same entity or event.
- Incorrect Data: This includes typos, invalid values, or data that doesn’t make sense in the context of your analysis.
- Outliers: Extreme values that don’t fit within the expected range of your data and may affect the results of your analysis.
- Inconsistent Data: Data stored in different formats or units that should be standardized.
Understanding these issues will help you know what to look for when cleaning your dataset.
3. Steps to Master Data Cleaning
Now that you know the types of problems you may face, here’s a step-by-step guide to mastering data cleaning for your high school data science projects.
3.1 Step 1: Understand Your Dataset
Before you start cleaning, it’s essential to get to know your dataset. This includes understanding:
- The structure of the data (rows, columns, and what each represents).
- The types of data in each column (e.g., numerical, categorical, text).
- The distribution of data, which can help you identify outliers or anomalies.
Use tools like pandas in Python or Excel to take a quick look at your data and generate basic statistics.
Relevant Resources:
3.2 Step 2: Handle Missing Data
Missing data is common in most datasets. You can handle it in several ways:
- Remove missing values: If the missing data is a small portion of the dataset and won't affect your analysis, you can remove these rows or columns.
- Impute missing values: For numerical data, you can fill in missing values with the mean, median, or mode. For categorical data, you can fill missing values with the most frequent category.
- Mark missing data: In some cases, it’s essential to mark missing data explicitly rather than removing or filling it, especially if the absence of data itself is informative.
Relevant Resources:
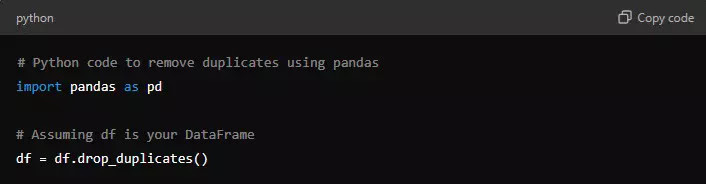
3.3 Step 3: Remove Duplicate Data
Duplicate records can distort your analysis by giving undue weight to certain data points. Use tools like pandas to identify and remove duplicates in your dataset:
Relevant Resources:
3.4 Step 4: Fix Incorrect Data
Check your dataset for any incorrect or inconsistent values. This might involve:
- Converting data types: Ensure that numerical data is stored as numbers, dates are in the correct format, etc.
- Validating data: Check if the values make sense in context. For example, a temperature value of 200°C in a dataset about weather would be a clear error.
You can use basic validation techniques or more advanced data validation libraries depending on the complexity of your project.
Relevant Resources:
3.5 Step 5: Handle Outliers
Outliers are data points that fall far outside the normal range of the rest of your data. While some outliers can be valid, others may be the result of measurement errors or data entry mistakes.
To handle outliers, you can:
- Remove outliers if they seem to be errors.
- Transform outliers by scaling or normalizing your data.
- Investigate outliers to determine if they provide valuable insights.
Relevant Resources:
3.6 Step 6: Standardize and Normalize Data
If your data is stored in different formats, you’ll need to standardize it for consistent analysis. This might involve:
- Converting units: For example, if you have heights recorded in both feet and meters, convert them to the same unit.
- Normalizing data: Normalize your numerical data so that it’s on a similar scale, especially if you are using machine learning algorithms.
Relevant Resources:
4. Tools for Data Cleaning
Here are some tools that can make data cleaning easier for your high school data science projects:
- Python (pandas): One of the most popular tools for data cleaning and manipulation in data science.
- Excel/Google Sheets: For smaller datasets, Excel or Google Sheets provide a simple interface for basic data cleaning tasks.
- OpenRefine: A powerful tool for cleaning messy data.
5. Practice with Real Datasets
To master data cleaning, practice is essential. Here are some places where you can find real-world datasets to clean and analyze:
By working with these datasets, you can apply the steps outlined in this article and become proficient in data cleaning.
Conclusion
Mastering data cleaning is a critical skill for any aspiring data scientist, and it’s especially valuable for high school students tackling their first data science projects. By understanding common data issues and using the right tools and techniques, you can ensure your data is accurate and ready for meaningful analysis. With practice, data cleaning will become second nature, allowing you to focus on uncovering insights and solving real-world problems with data.
{kind=link}